ÖVERGRIPANDE DOM
Av 10
Fördelar
- Ett snabbt och pålitligt nätverk för att arbeta med data.
- Operativt stöd.
- Enkel och effektiv att använda.
- Operativt stöd.
- Flexibla prisplaner.
Nackdelar
- Absolut inte den billigaste tjänsten som finns.
Är du trött på att bli blockerad när du försöker skrapa data från webbplatser? Leta inte längre än Bright Datas Scraping Browser.
Den här innovativa lösningen är utrustad med inbyggda funktioner för avblockering av webbplatser, inklusive CAPTCHA-lösning, automatiska återförsök och mer, vilket gör dataskrapa till en lek.
Men ta inte bara vårt ord för det – med en framgångsgrad på över 90 % är det inte konstigt att Scraping Browser är den bästa lösningen för företag och utvecklare som vill skala sina dataskrapningsprojekt.
Så varför fortsätta kämpa med att komma förbi webbplatsblockeringar när Scraping Browser kan göra allt åt dig?
Innehåll
- Vad är scraping webbläsare och varför använda dem?
- Vad är Bright Data Scraping Browser?
- Funktioner i Bright Data Scraping Browser
- Bright Data Scraping Browser – Stora fördelar
- Bright Data Scraping Browser & Hur man köper guide
- Varför rekommenderar jag att du använder Bright Data Scraping Browser?
- Slutsats: Bright Data Scraping Browser Review 2024
Vad är scraping webbläsare och varför använda dem?
En scraping-webbläsare är en automatisk webbläsare som kodare använder för att få information. Det kan styras av API:er på hög nivå som Puppeteer och Playwright, och det har inbyggda sätt att avblockera webbplatser.
En scraping-webbläsare skiljer sig från en tom webbplats genom att den har ett grafiskt användargränssnitt (GUI) som låter dig välja hur det fungerar.
När utvecklare skrapar data använder de automatiska webbläsare för att rendera en sida i JavaScript eller ansluta till en webbplats. Till exempel flytta, byta sida, klicka och till och med ta skärmdumpar. Dessutom kan webbläsare hjälpa till med stora projekt som behöver skrapa data från många sidor samtidigt.
En scraping-webbläsare är ett mycket bättre sätt att skala dataskrapningsprojekt och komma runt block än att använda tomma webbläsare. Huvudlösa webbläsare har inte ett användargränssnitt som du kan se.
Vid skrapning av data används dessa webbläsare ofta med proxyservrar, men programvara som skyddar mot bots kan lätt hitta dem. Detta gör det svårt att samla in mycket data på en gång.
Att Bright Datas datorer kan öppna Scraping Browser är också ett plus. På grund av detta är det bra för projekt som behöver göras större.
Utvecklare kan öppna så många scraping-webbläsare som de vill utan att behöva betala för ett dyrt system på sina egna datorer.
Dessutom är det mindre sannolikt att programvara som letar efter bots hittar Scraping Browser eftersom den har ett GUI-gränssnitt. Detta gör det till ett bättre verktyg för att skrapa data som folk kan lita på.
Vad är Bright Data Scraping Browser?
Smakämnen Bright Data Scraping Browser är en automatiserad allt-i-ett-webbläsare som är gjord för att skrapa data. Det drivs av ett proxynätverk som har vunnit priser och har mer än 72 miljoner IP-adresser och möjligheten att rikta sig mot vilket land, stad, operatör eller ASN som helst.
Denna betalda proxytjänst är det bästa alternativet för utvecklare som behöver skrapa mycket data. Det fungerar också med Puppeteer, vilket gör det starkare än automatiska och huvudlösa webbläsare.
Bright Data Scraping Browser är gjord för att skrapa data snabbt, enkelt och säkert. Den använder högteknologiska verktyg som AI-drivna captchas och botdetektering för att säkerställa det datauttag går smidigt.
Med Bright Data Scraping Browser kan användare enkelt och snabbt få information från vilken webbplats som helst på ett säkert sätt.
Funktioner i Bright Data Scraping Browser
Webbskrapning i stor skala görs enklare med Bright Datas scraping-webbläsare.
1. Automatisk hantering av webblåsningsoperationer
En viktig del av programmet är att det hanterar processen att låsa upp webbplatser automatiskt. Det innebär bland annat att göra saker som att lösa CAPTCHA och få fingeravtryck från webbläsare.
Detta kan spara tid och pengar för utvecklare om de behöver få mycket data från webbplatser.
2. Överlista mjukvara för botdetektering
En annan viktig sak om Bright Datas scraping-webbläsare är att det kan lura programvara som letar efter bots.
Inte bara kan skrapor använda AI-teknik för att komma runt bot-detektionssystem, men de kan också få bättre öppningshastigheter när de använder proxy istället för AI-teknik.
3. Mycket skalbar
Bright Datas scraping-webbläsare är också lätt att skala upp, så utvecklare kan lägga till så många webbläsare som de behöver till sina scraping-projekt när de växer.
Webbläsarna är inrymda på Bright Datas infrastruktur, som är gjord för att hantera mycket trafik och förfrågningar.
4. Kompatibel med både Puppeteer (Python) och Playwright (Node.js)
Slutligen fungerar Bright Datas scraping-webbläsare med både Puppeteer (Python) och Playwright (Node.js), vilket låter utvecklare hantera webbläsarsessioner och interagera med webbplatser för att få data.
Detta kan hjälpa till med att skrapa projekt som kräver att man trycker på knappar, rullar eller lägger till text på webbsidor.
Bright Data Scraping Browser – Stora fördelar
Bright Data Scraping Browser är en automatisk webbläsare som kan göra allt. Den var gjord för att skrapa data. Den har många funktioner och förmåner som gör den till ett pålitligt verktyg för dataskrapningsprojekt. Här är några av dess viktigaste fördelar:

1. Sparar resurser och tid:
Bright Data Scraping-webbplatsen ger dig en webbplats som kan göra allt, vilket sparar tid, pengar och andra resurser.
Med Scraping Browser behöver tillverkarna inte bygga sin egen infrastruktur eller förlita sig på tredjepartstjänster för att öppna. Webbläsaren är inställd så att det är lätt att skrapa data, vilket gör den till ett användbart verktyg som sparar tid och pengar.
2. Idealisk för skalning:
Skalbarhet är en av de viktigaste fördelarna med att använda Bright Data Scraping Browser. Webbläsaren kan hantera tiotusentals sessioner samtidigt om den är sparad på Bright Data-servern.
På grund av detta är det bra för projekt som behöver skrapa mycket data från många sidor samtidigt. Scraping Browser är gjord för att hantera flera sessioner, vilket gör den till ett bra verktyg för att få information från många webbplatser samtidigt.
3. Avblockerar webbplatser åt dig:
En av de svåraste delarna av dataskrapning är att komma runt webbplatsblockeringar. Bright Data Scraping Browser hanterar nya block, CAPTCHAs, fingeravtryck och försöker snabbt igen och ser ut som en riktig användare.
Kodare behöver inte oroa sig för att avblockera webbplatser för hand eller betala för tredjepartstjänster när de använder Scraping Browser.
4. Puppteer kompatibel:
Bright Data Scraping Browser fungerar med Puppeteer, som är ett välkänt API för att skrapa data. Detta gör Scraping Browser bättre på att komma runt verktyg och webbplatsblock som letar efter bots än automatiska och tomma webbläsare.
Med Puppeteer får utvecklare mer frihet och makt över hur webbläsaren fungerar. Detta gör det enklare och mer tillförlitligt att skrapa information.
Bright Data Scraping Browser & Hur man köper guide
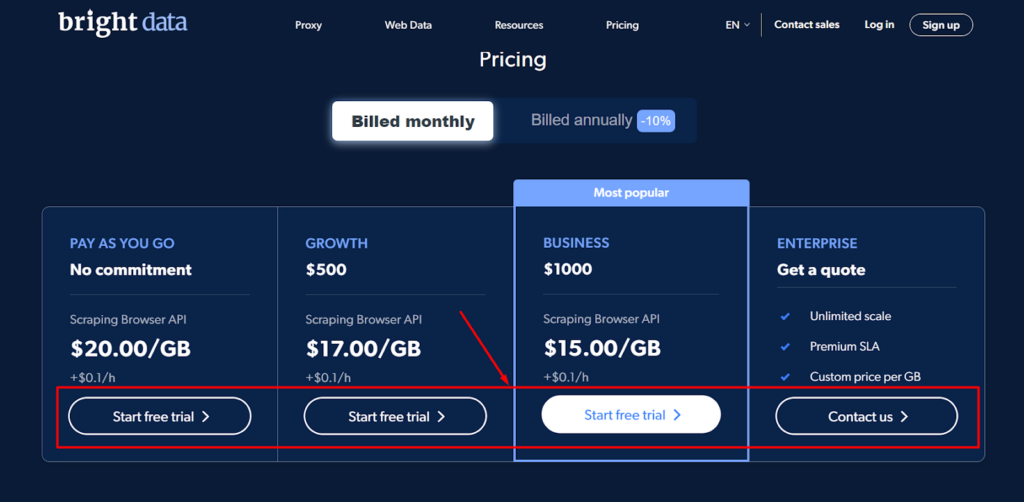
Steg - 1: Besök webbplatsen Bright Data Scraping Browser och välj din föredragna plan.
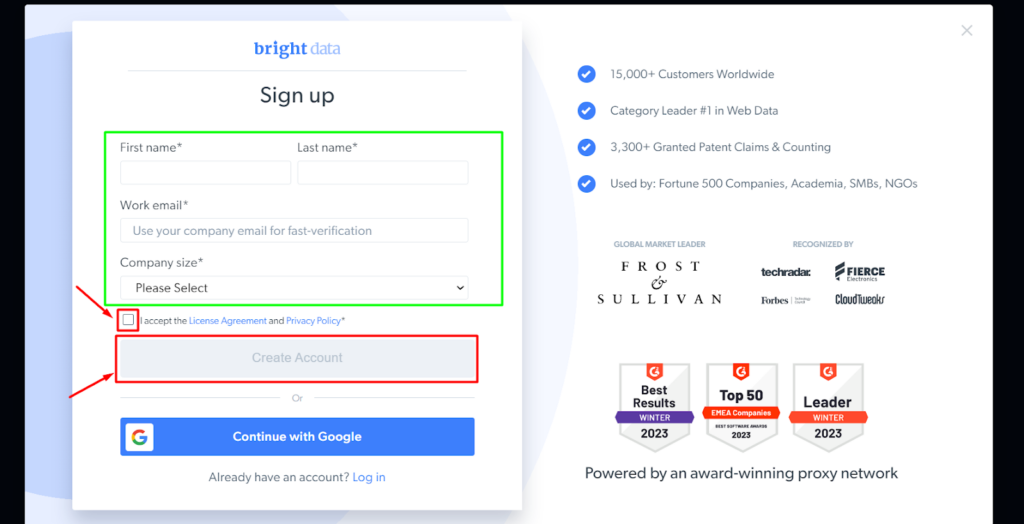
Steg - 2: Ange den begärda informationen, markera rutan och klicka på "Skapa konto".
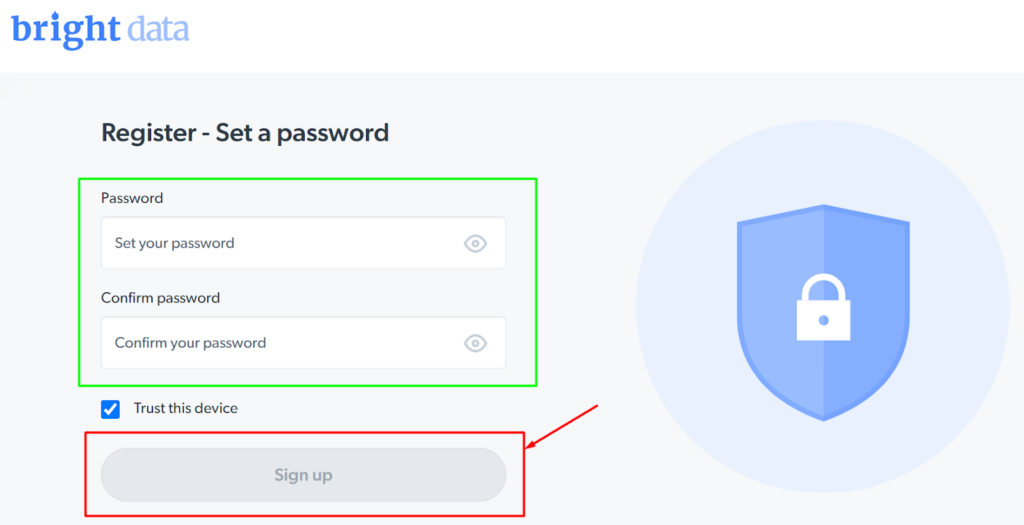
Steg - 3: Fyll i registreringsformuläret och klicka på knappen "Registrera dig".
Steg - 4: Gå till Bright Data Scraping Browser och klicka på "Kom igång".
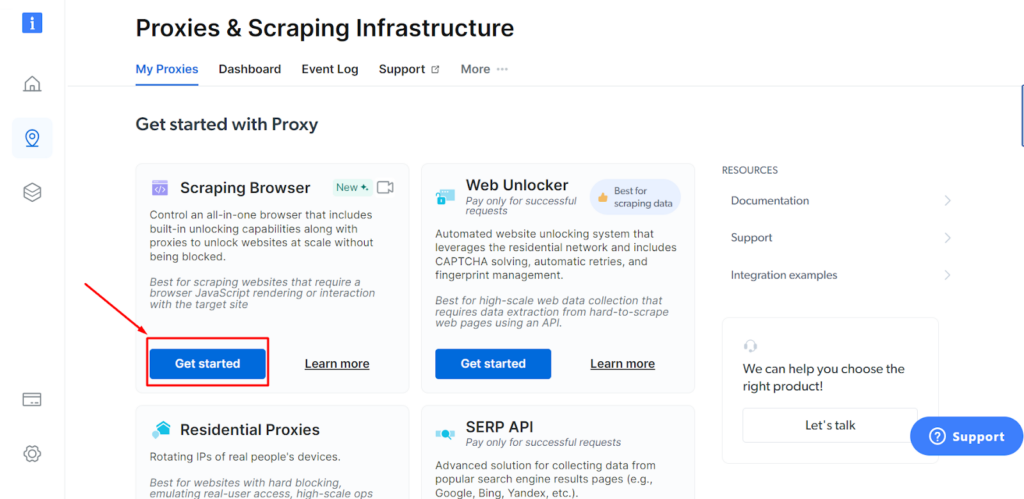
Steg - 5: Klicka på knappen "Spara och aktivera".
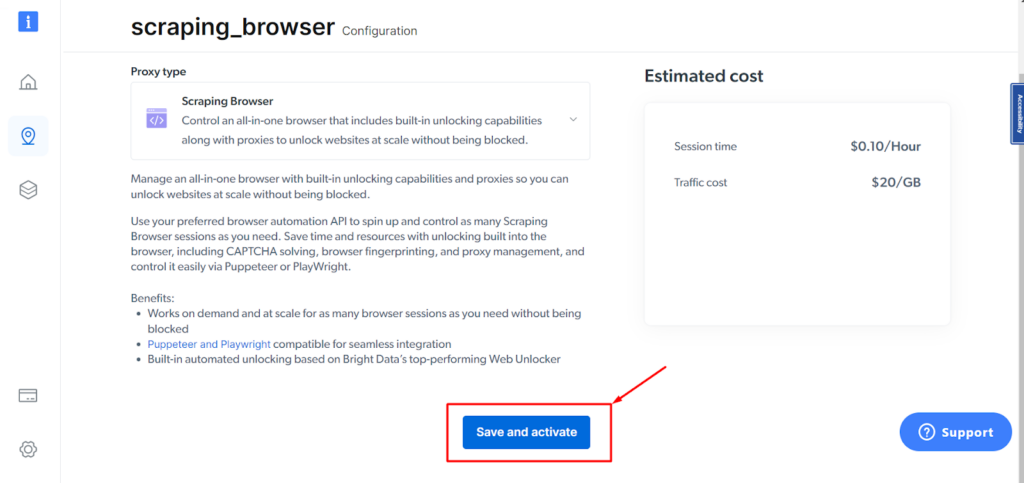
Steg - 6: Fyll i faktureringsinformationen och klicka sedan på "Spara adress".
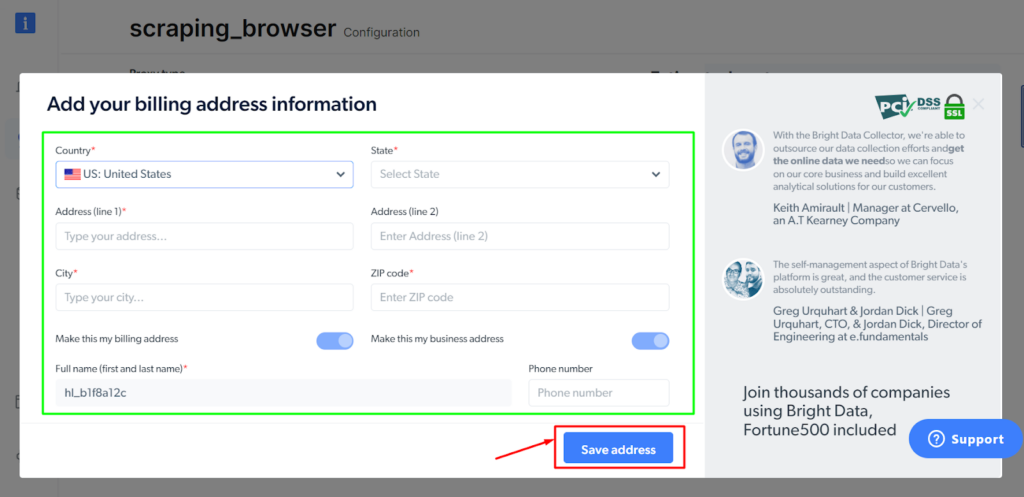
När du har slutfört betalningen är allt klart.
Låt mig diskutera prissättningsplanerna så att det är lättare för dig att göra valet:
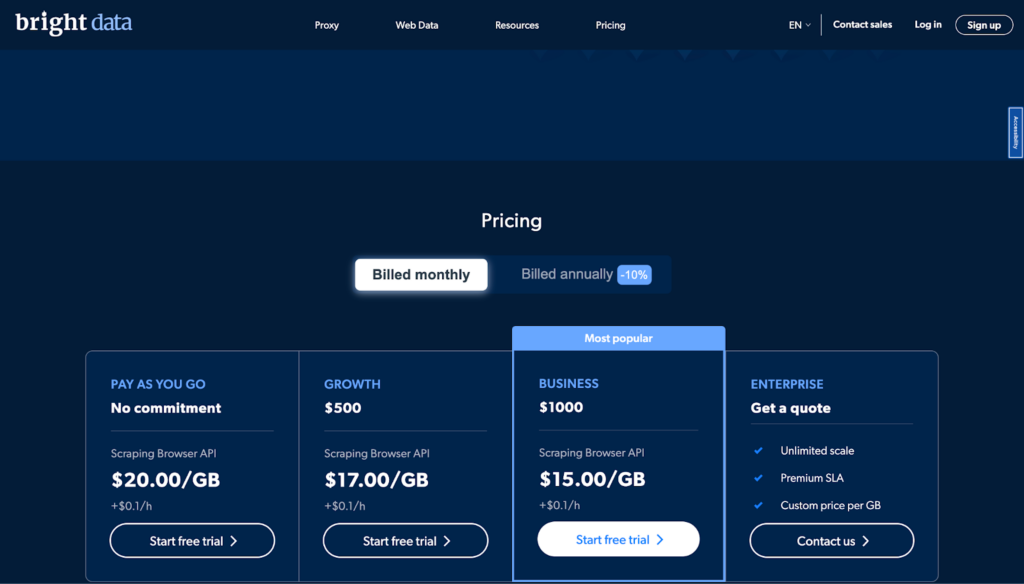
Bright Data Scraping Browser är prissatt så att företag av alla storlekar, från små startups till stora företag, har råd med det. Företaget har fyra prissättningsalternativ, inklusive Pay As You Go, Growth, Business och Enterprise, för att möta behoven hos olika användare.
Pay As You Go-planen är gjord för personer som bara behöver skrapa små mängder eller små mängder data då och då. Det är en plan utan åtaganden som låter dig betala endast för det du använder. Denna plan kostar $20.00 per gigabyte + $0.1 per timme.
Tillväxtplanen är perfekt för företag som behöver skrapa mer eller mer omfattande mängder data. Det kostar $500 per månad och ger dig 10 % besparing på Pay As You Go-planen. Denna plan kostar $17.00 per gigabyte plus $0.1 per timme.
Den mest populära planen är affärsplanen, som är gjord för företag som vill utöka sina dataskrapningsaktiviteter. Det kostar $1000 per månad och ger dig 25% besparing på Pay As You Go-planen. Denna plan kostar $15.00 per gigabyte + $0.1 per timme.
Slutligen är Enterprise-planen gjord för företag som behöver ett SLA (service level agreement) och kan växa till vilken storlek som helst. Priset för denna plan baseras på dina unika behov och krav och är gjorda just för dig.
Den här planen har fördelar som en dedikerad kontoansvarig, anpassad prissättning per GB och support tillgänglig 24 timmar om dygnet, 7 dagar i veckan.
Dessutom kan du betala årligen och spara upp till 40 % om du vill SPARA mer.
Varför rekommenderar jag att du använder Bright Data Scraping Browser?
Bright Data Scraping Browser är en typ av webbläsare som kan användas automatiskt för att hämta data. Här är några anledningar till varför jag tycker att du bör använda den här webbläsaren för dina projekt som involverar att skrapa data:
1. Kompatibel med dockspelare och dramatiker:
Bright Data Scraping Browser fungerar med två kända API:er för att automatisera dataskrapning: Puppeteer (Python) och Playwright (Node.js).
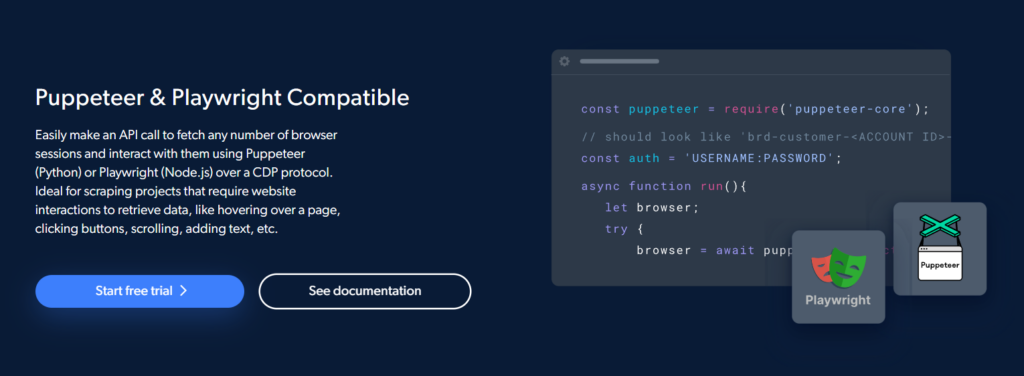
Detta gör det enkelt för programmerare att få så många webbläsarsessioner som de behöver och använda Puppeteer eller Playwright för att arbeta med dem över ett CDP-gränssnitt.
2. Skalbarhet:
Bright Data Scraping Browser hålls på Bright Datas dator, vilket är mycket skalbart. Detta gör det bra för växande projekt som skrapar information från webben.
Med Scraping Browser kan utvecklare lägga till så många webbläsare som de behöver till sina dataskrapningsprojekt utan att behöva bygga ett dyrt system internt.
3. Överlista alla bot-detektionsprogram:
Systemen som hittar bots blir bättre, vilket gör det svårare och svårare att komma runt dem.
Men Bright Data Scraping Browser använder AI för att automatiskt lära sig hur man tar sig runt dessa system när de förändras, så att utvecklare inte behöver ta itu med besväret och kostnaderna för att använda tjänster från tredje part.
System som letar efter bots ser Scraping Browser som en riktig användares webbläsare, vilket gör den lättare att öppna än proxyservrar.
4. Förbi de tuffaste webbplatsblocken:
Bright Data Scraping Browser hanterar alla jobb för att låsa upp webbplatser direkt och utom synhåll. Detta inkluderar JavaScript-rendering, cookies, plockningsdata, automatiska återförsök, webbläsarfingeravtryck, korrigering av CAPTCHA och mer.

Detta verktyg sparar utvecklare mycket tid och pengar, särskilt när de måste göra svåra saker för att öppna mycket data.
Snabblänkar:
- Nimbleway recension
- Rocket.net recension
- 9 Bästa Sneaker Proxy Providers
- 10 bästa mobilproxyleverantörer
Slutsats: Bright Data Scraping Browser Review 2024
Bright Data Scraping Browser är ett kraftfullt verktyg för att skrapa data som har ett antal funktioner och fördelar som kan hjälpa dig att få dina skrapningsprojekt att gå smidigare.
Med sin förmåga att öppna webbplatser snabbt, dess kompatibilitet med Puppeteer och Playwright, dess skalbarhet och dess AI-teknik kan den här webbläsaren spara tid och pengar samtidigt som den ger dig en bättre chans att lyckas än proxyservrar.
Dess förmåga att automatiskt låsa upp webbplatser gör det till ett utmärkt verktyg för att skrapa i stora mängder, där komplexa upplåsningsprocesser behövs.
Oavsett om du driver ett litet företag eller ett stort företag, är Bright Data Scraping Browser ett pålitligt verktyg som kan hjälpa dig att effektivisera dina dataskrapningsoperationer och få användbar information från internet.