GESAMTURTEIL
Aus 10 heraus
Vorteile
- Ein schnelles, zuverlässiges Netzwerk für die Arbeit mit Daten.
- Operative Unterstützung.
- Einfach und effizient zu bedienen.
- Operative Unterstützung.
- Flexible Preispläne.
Nachteile
- Sicherlich nicht der günstigste Service.
Sind Sie es leid, blockiert zu werden, während Sie versuchen, Daten von Websites zu kratzen? Suchen Sie nicht weiter als nach dem Scraping Browser von Bright Data.
Diese innovative Lösung ist mit integrierten Funktionen zum Entsperren von Websites ausgestattet, darunter CAPTCHA-Auflösung, automatische Wiederholungen und mehr, wodurch das Daten-Scraping zum Kinderspiel wird.
Aber verlassen Sie sich nicht nur auf uns – mit einer Erfolgsquote von über 90 % ist es kein Wunder, dass Scraping Browser die Lösung der Wahl für Unternehmen und Entwickler ist, die ihre Data-Scraping-Projekte skalieren möchten.
Warum also weiterhin damit kämpfen, Website-Blockaden zu überwinden, wenn Scraping Browser alles für Sie erledigen kann?
Inhalte
- Was sind Scraping-Browser und warum werden sie verwendet?
- Was ist der Bright Data Scraping Browser?
- Funktionen des Bright Data Scraping Browsers
- Bright Data Scraping Browser – Hauptvorteile
- Bright Data Scraping Browser & Kaufanleitung
- Warum empfehle ich die Verwendung des Bright Data Scraping Browsers?
- Fazit: Bright Data Scraping Browser Review 2024
Was sind Scraping-Browser und warum werden sie verwendet?
Ein Scraping-Browser ist ein automatischer Browser, mit dem Programmierer Informationen abrufen. Es kann von High-Level-APIs wie Puppeteer und Playwright gesteuert werden und verfügt über integrierte Möglichkeiten zum Entsperren von Websites.
Ein Scraping-Browser unterscheidet sich von einer leeren Website dadurch, dass er über eine grafische Benutzeroberfläche (GUI) verfügt, mit der Sie auswählen können, wie er funktioniert.
Wenn Entwickler Daten kratzen, verwenden sie automatische Browser, um eine Seite in JavaScript zu rendern oder eine Verbindung zu einer Website herzustellen. Zum Beispiel bewegen, Seiten wechseln, klicken und sogar Screenshots machen. Außerdem können Browser bei großen Projekten helfen, die Daten von vielen Seiten gleichzeitig abkratzen müssen.
Ein Scraping-Browser ist eine viel bessere Möglichkeit, Data-Scraping-Projekte zu skalieren und Blöcke zu umgehen, als leere Browser zu verwenden. Headless-Browser haben keine sichtbare Benutzeroberfläche.
Beim Scraping von Daten werden diese Browser oft mit Proxys verwendet, aber Software, die schützt vor Bots kann sie leicht finden. Das macht es schwierig, viele Daten auf einmal zu sammeln.
Die Tatsache, dass die Computer von Bright Data Scraping Browser öffnen können, ist ebenfalls ein Pluspunkt. Aus diesem Grund eignet es sich hervorragend für Projekte, die größer werden müssen.
Entwickler können beliebig viele Scraping-Browser öffnen, ohne für ein teures System auf ihren eigenen Computern bezahlen zu müssen.
Außerdem ist es weniger wahrscheinlich, dass Software, die nach Bots sucht, den Scraping Browser findet, da er über eine GUI-Oberfläche verfügt. Dies macht es zu einem besseren Tool zum Scraping von Daten, denen die Menschen vertrauen können.
Was ist der Bright Data Scraping Browser?
Das Heller Data-Scraping-Browser ist ein automatisierter All-in-One-Browser, der zum Scraping von Daten entwickelt wurde. Es wird von einem preisgekrönten Proxy-Netzwerk betrieben, das über mehr als 72 Millionen IPs verfügt und die Möglichkeit hat, jedes Land, jede Stadt, jede Fluggesellschaft oder jeden ASN anzusprechen.
Dieser kostenpflichtige Proxy-Dienst ist die beste Option für Entwickler, die viele Daten kratzen müssen. Es funktioniert auch mit Puppeteer, was es stärker macht als automatisierte und kopflose Browser.
Der Bright Data Scraping Browser wurde entwickelt, um das Scraping von Daten schnell, einfach und sicher zu machen. Es verwendet High-Tech-Tools wie KI-gesteuerte Captchas und Bot-Erkennung, um dies sicherzustellen Datenextraktion geht reibungslos.
Mit dem Bright Data Scraping Browser können Benutzer auf sichere Weise einfach und schnell Informationen von jeder Website abrufen.
Funktionen des Bright Data Scraping Browsers
Skaliertes Web-Scraping wird mit dem Scraping-Browser von Bright Data vereinfacht.
1. Automatische Verwaltung von Website-Entsperrvorgängen
Ein wichtiger Teil des Programms besteht darin, dass es den Prozess des automatischen Entsperrens von Websites übernimmt. Das bedeutet unter anderem, Dinge wie das Lösen von CAPTCHAs und das Abrufen der Fingerabdrücke von Browsern zu tun.
Dies kann Entwicklern Zeit und Geld sparen, wenn sie viele Daten von Websites abrufen müssen.
2. Software zur Bot-Erkennung überlisten
Noch eine wichtige Sache über Scraping-Browser von Bright Data ist, dass es Software täuschen kann, die nach Bots sucht.
Kann nicht nur Schaber verwenden KI-Technologie um Bot-Erkennungssysteme zu umgehen, aber sie können auch bessere Öffnungsraten erzielen, wenn sie Proxys anstelle von KI-Technologie verwenden.
3. Hochgradig skalierbar
Der Scraping-Browser von Bright Data lässt sich auch einfach skalieren, sodass Entwickler ihren Scraping-Projekten so viele Browser hinzufügen können, wie sie benötigen, wenn sie wachsen.
Die Browser sind in der Infrastruktur von Bright Data untergebracht, die darauf ausgelegt ist, viel Verkehr und Anfragen zu bewältigen.
4. Kompatibel mit Puppeteer (Python) und Playwright (Node.js)
Schließlich funktioniert der Scraping-Browser von Bright Data sowohl mit Puppeteer (Python) als auch mit Playwright (Node.js), wodurch Entwickler mit Browsersitzungen umgehen und mit Websites interagieren können, um Daten zu erhalten.
Dies kann beim Scraping von Projekten helfen, bei denen Schaltflächen gedrückt, gescrollt oder Text zu Webseiten hinzugefügt werden müssen.
Bright Data Scraping Browser – Hauptvorteile
Bright Data Scraping Browser ist ein automatischer Browser, der alles kann. Es wurde zum Scrapen von Daten entwickelt. Es hat viele Funktionen und Vorteile, die es zu einem zuverlässigen Tool für Data-Scraping-Projekte machen. Hier sind einige der wichtigsten Vorteile:

1. Spart Ressourcen & Zeit:
Die Bright Data Scraping-Website bietet Ihnen eine Website, die alles kann, wodurch Sie Zeit, Geld und andere Ressourcen sparen.
Mit dem Scraping Browser müssen Hersteller keine eigene Infrastruktur aufbauen oder sich zum Öffnen auf Dienste von Drittanbietern verlassen. Der Browser ist so eingerichtet, dass es einfach ist, Daten zu kratzen, was ihn zu einem nützlichen Werkzeug macht, das Zeit und Geld spart.
2. Ideal zum Skalieren:
Skalierbarkeit ist einer der wichtigsten Vorteile der Verwendung von Bright Data Scraping Browser. Der Browser kann Zehntausende von Sitzungen gleichzeitig verarbeiten, wenn er auf dem Bright Data-Server gespeichert wird.
Aus diesem Grund eignet es sich hervorragend für Projekte, die viele Daten von vielen Seiten gleichzeitig entfernen müssen. Der Scraping-Browser ist darauf ausgelegt, mehrere Sitzungen zu verarbeiten, was ihn zu einem guten Werkzeug macht, um Informationen von vielen Websites gleichzeitig zu erhalten.
3. Entsperrt Websites für Sie:
Einer der schwierigsten Teile des Data Scraping ist das Umgehen von Website-Blöcken. Der Bright Data Scraping Browser verarbeitet neue Blöcke, CAPTCHAs, Fingerabdrücke und Wiederholungen schnell und sieht aus wie ein echter Benutzer.
Programmierer müssen sich keine Gedanken darüber machen, Websites manuell zu entsperren oder für Dienste von Drittanbietern zu bezahlen, wenn sie den Scraping-Browser verwenden.
4. Puppenspieler-kompatibel:
Der Bright Data Scraping Browser arbeitet mit Puppeteer, einer bekannten API zum Scraping von Daten. Dadurch kann der Scraping-Browser Tools und Website-Blöcke, die nach Bots suchen, besser umgehen als automatische und leere Browser.
Mit Puppeteer haben Entwickler mehr Freiheit und Kontrolle darüber, wie der Browser funktioniert. Dies macht es einfacher und zuverlässiger, Informationen zu kratzen.
Bright Data Scraping Browser & Kaufanleitung
Schritt - 1: Besuchen Sie die Bright Data Scraping Browser-Website und wählen Sie Ihren bevorzugten Plan aus.
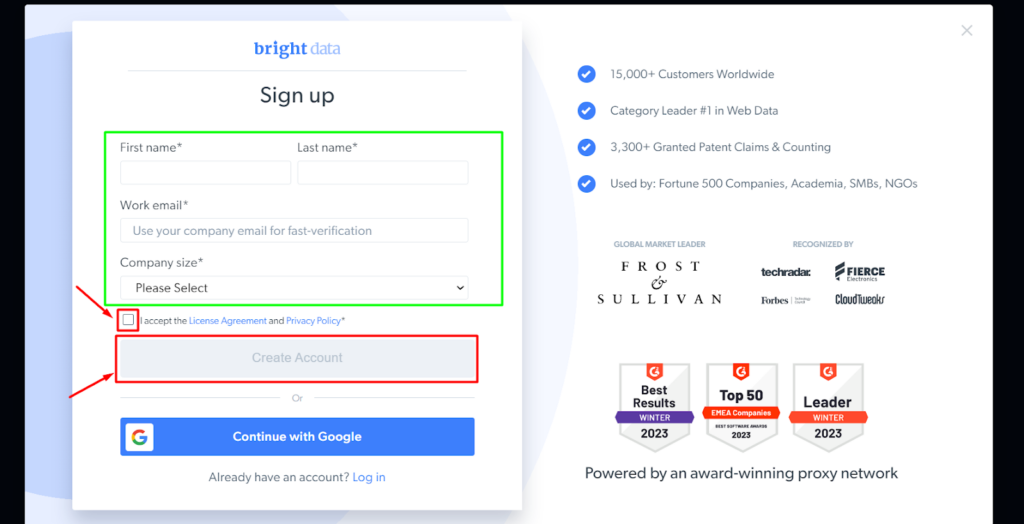
Schritt - 2: Geben Sie die angeforderten Informationen ein, aktivieren Sie das Kontrollkästchen und klicken Sie auf „Konto erstellen“.
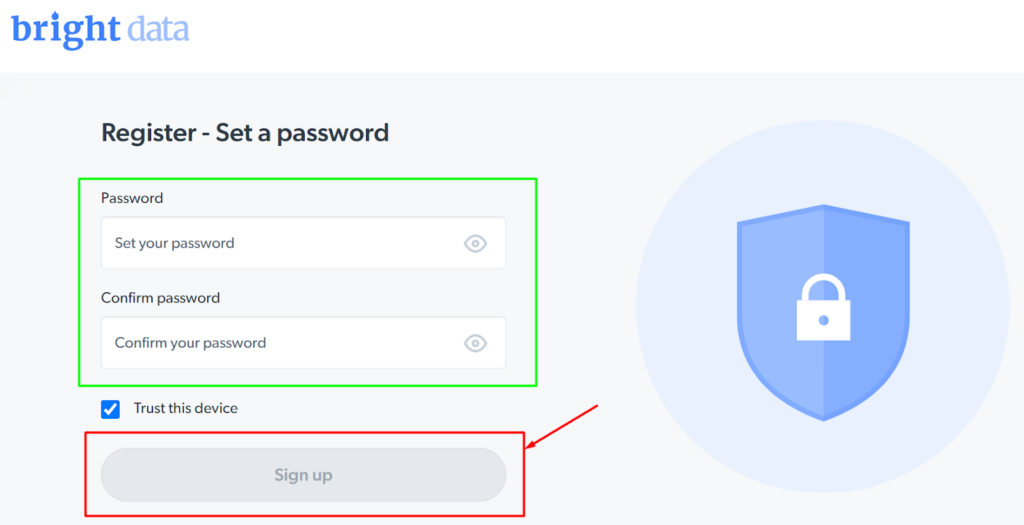
Schritt - 3: Füllen Sie das Anmeldeformular aus und klicken Sie auf die Schaltfläche „Anmelden“.
Schritt - 4: Gehen Sie zum Bright Data Scraping Browser und klicken Sie auf „Erste Schritte“.
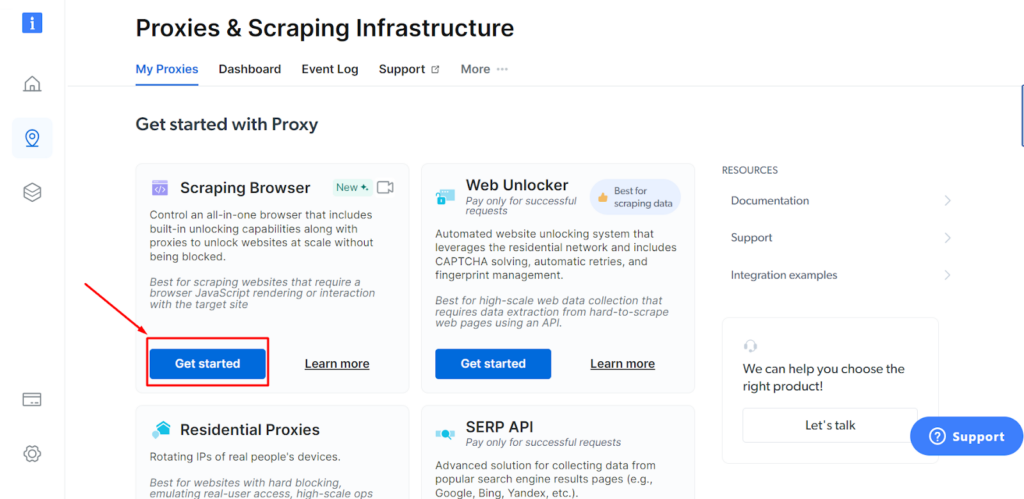
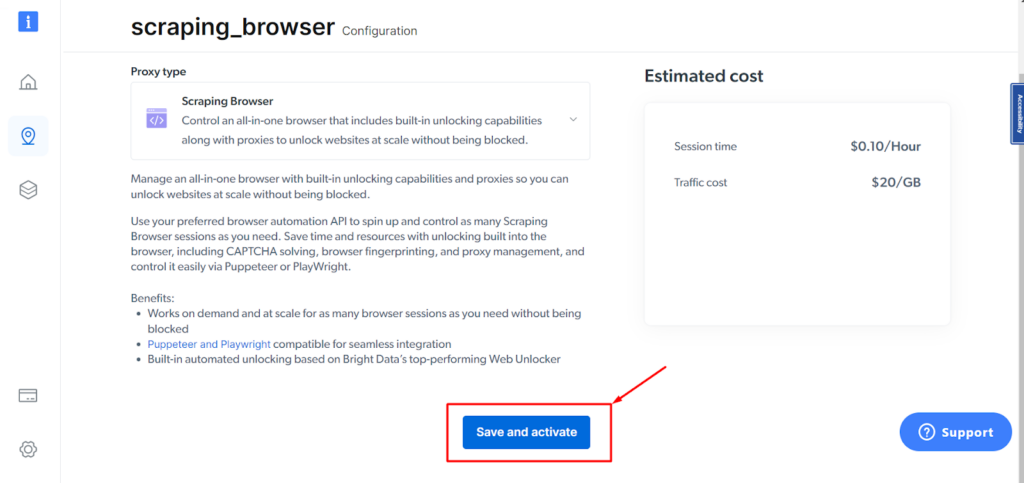
Schritt - 5: Klicken Sie auf die Schaltfläche „Speichern und aktivieren“.
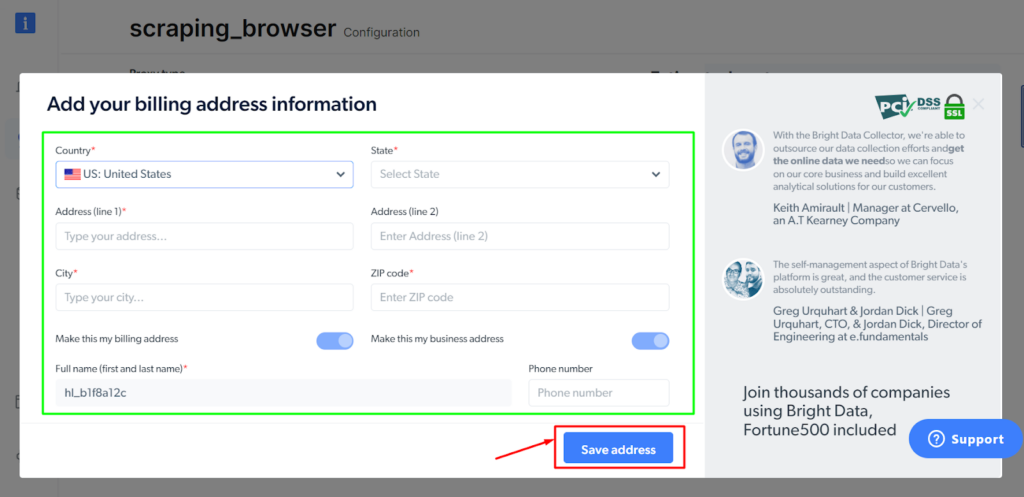
Schritt - 6: Vervollständigen Sie die Rechnungsinformationen und klicken Sie dann auf „Adresse speichern“.
Nachdem Sie die Zahlung abgeschlossen haben, sind Sie fertig.
Lassen Sie mich die Preispläne besprechen, damit Sie die Wahl leichter treffen können:
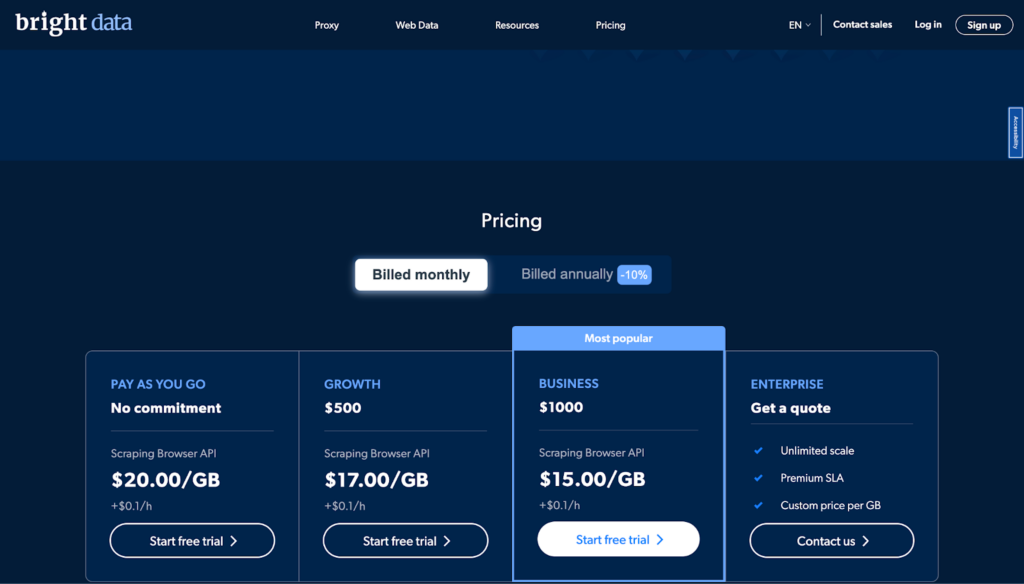
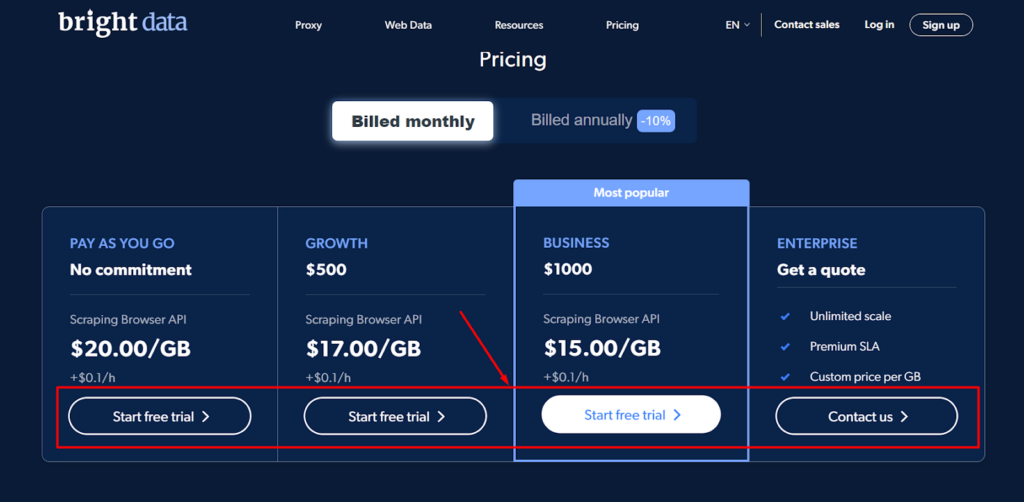
Der Preis für den Bright Data Scraping Browser ist so hoch, dass sich Unternehmen jeder Größe, von kleinen Startups bis hin zu großen Konzernen, ihn leisten können. Das Unternehmen bietet vier Preisoptionen an, darunter Pay As You Go, Growth, Business und Enterprise, um den Anforderungen verschiedener Benutzer gerecht zu werden.
Der Pay As You Go-Plan ist für Personen gedacht, die von Zeit zu Zeit nur kleine Mengen oder kleine Datenmengen kratzen müssen. Es ist ein Plan ohne Verpflichtungen, bei dem Sie nur für das bezahlen, was Sie nutzen. Dieser Plan kostet 20.00 $ pro Gigabyte + 0.1 $ pro Stunde.
Der Wachstumsplan ist perfekt für Unternehmen, die mehr oder größere Datenmengen kratzen müssen. Es kostet 500 $ pro Monat und gibt Ihnen 10 % Ersparnis gegenüber dem Pay-As-You-Go-Plan. Dieser Plan kostet 17.00 USD pro Gigabyte plus 0.1 USD pro Stunde.
Der beliebteste Plan ist der Business-Plan, der für Unternehmen entwickelt wurde, die ihre Data-Scraping-Aktivitäten ausbauen möchten. Es kostet 1000 $ pro Monat und gibt Ihnen eine Ersparnis von 25 % gegenüber dem Pay-As-You-Go-Plan. Dieser Plan kostet 15.00 $ pro Gigabyte + 0.1 $ pro Stunde.
Schließlich ist der Enterprise-Plan für Unternehmen gedacht, die ein SLA (Service Level Agreement) benötigen und auf jede Größe wachsen können. Der Preis für diesen Plan basiert auf Ihren individuellen Bedürfnissen und Anforderungen und wird nur für Sie erstellt.
Dieser Plan bietet Vorteile wie einen dedizierten Account Manager, benutzerdefinierte Preise pro GB und Support, der 24 Stunden am Tag, 7 Tage die Woche verfügbar ist.
Sie können auch jährlich zahlen und bis zu 40 % sparen, wenn Sie mehr SPAREN möchten.
Warum empfehle ich die Verwendung des Bright Data Scraping Browsers?
Bright Data Scraping Browser ist ein Browsertyp, der automatisch zum Abrufen von Daten verwendet werden kann. Hier sind einige Gründe, warum Sie diesen Browser meiner Meinung nach für Ihre Projekte verwenden sollten, bei denen Daten gescrapt werden:
1. Kompatibel mit Puppenspielern und Dramatikern:
Bright Data Scraping Browser arbeitet mit zwei bekannten APIs zur Automatisierung von Data Scraping: Puppeteer (Python) und Playwright (Node.js).
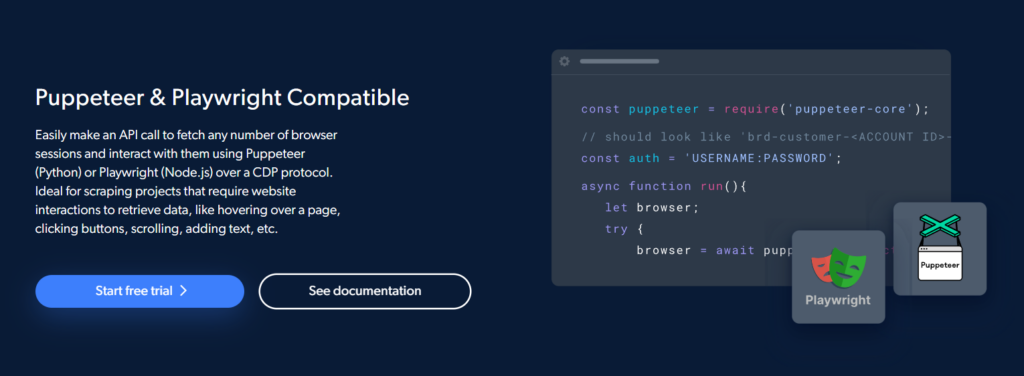
Dies macht es Programmierern leicht, so viele Browsersitzungen wie nötig zu erhalten und Puppeteer oder Playwright zu verwenden, um mit ihnen über eine CDP-Schnittstelle zu arbeiten.
2. Skalierbarkeit:
Der Bright Data Scraping Browser wird auf dem Computer von Bright Data gespeichert, der sehr skalierbar ist. Dies macht es ideal für wachsende Projekte, die Informationen aus dem Internet kratzen.
Mit Scraping Browser können Entwickler ihren Daten-Scraping-Projekten beliebig viele Browser hinzufügen, ohne ein teures System intern aufbauen zu müssen.
3. Überlisten Sie jede Bot-Erkennungssoftware:
Die Systeme, die Bots finden, werden immer besser, was es immer schwieriger macht, sie zu umgehen.
Aber Bright Data Scraping Browser verwendet KI, um automatisch zu lernen, wie diese Systeme umgangen werden können, wenn sie sich ändern, sodass sich Entwickler nicht mit den Problemen und Kosten der Nutzung von Diensten von Drittanbietern auseinandersetzen müssen.
Systeme, die nach Bots suchen, sehen den Scraping-Browser als Browser eines echten Benutzers, wodurch er einfacher zu öffnen ist als Proxys.
4. Umgehen Sie die härtesten Website-Sperren:
Der Bright Data Scraping Browser erledigt alle Jobs zum Entsperren von Websites sofort und außer Sichtweite. Dazu gehören JavaScript-Rendering, Cookies, Datenauswahl, automatische Wiederholungen, Browser-Fingerprinting, CAPTCHA-Korrektur und mehr.

Dieses Tool spart Entwicklern viel Zeit und Geld, insbesondere wenn sie schwierige Dinge tun müssen, um viele Daten zu öffnen.
Quick-Links:
- Nimbleway-Rezension
- Rocket.net Bewertung
- Die 9 besten Sneaker-Proxy-Anbieter
- Die 10 besten mobilen Proxy-Anbieter
Fazit: Bright Data Scraping Browser Review 2024
Bright Data Scraping Browser ist ein leistungsstarkes Tool zum Scraping von Daten, das über eine Reihe von Funktionen und Vorteilen verfügt, die Ihnen helfen können, Ihre Scraping-Projekte reibungsloser zu gestalten.
Mit seiner Fähigkeit, Websites schnell zu öffnen, seiner Kompatibilität mit Puppeteer und Playwright, seiner Skalierbarkeit und seiner KI-Technologie kann dieser Browser Ihnen Zeit und Geld sparen und bietet Ihnen gleichzeitig bessere Erfolgschancen als Proxys.
Seine Fähigkeit, Websites automatisch zu entsperren, macht es zu einem großartigen Tool zum Scrapen in großen Mengen, wenn komplexe Entsperrprozesse erforderlich sind.
Egal, ob Sie ein kleines Unternehmen oder ein großes Unternehmen führen, der Bright Data Scraping Browser ist ein zuverlässiges Tool, mit dem Sie Ihre Data Scraping-Vorgänge optimieren und nützliche Informationen aus dem Internet abrufen können.